Làm quen với mô hình MapReduce
1. Giới thiệu
MapReduce là một mô hình nổi tiếng trong tính toán phân tán, được giới thiệu trong bài báo MapReduce. Một chương trình viết theo mô hình MapReduce có khả năng chia nhỏ một công việc (1 job) để tiến hành song song, sau đó kết hợp các kết quả lại để cho ra kết quả cuối cùng.
Bài này sẽ dành để giới thiệu về MapReduce. Sau đó bài sẽ giới thiệu về bài tập MapReduce được lấy từ lớp distributed system của MIT. Bài tập này sử dụng ngôn ngữ lập trình Go.
2. Làm quen với mô hình MapReduce
Để hiểu hơn về MapReduce, chúng ta cùng xem chu trình để thực hiện một job của MapReduce.
- Đọc dữ liệu đầu vào: Dữ liệu đầu vào có thể là một file input hoặc một tập hợp nhiều file input. Nếu một file input quá lớn ta có thể chia nhỏ file ra làm nhiều file khác nhau. Ý tưởng ở đây là, mỗi một file input sẽ được xử lý bởi một map task.
- Xử lý dữ liệu đầu vào: Thực hiện Map, trộn/kết hợp các kết quả tạo ra các file output trung gian.
- Đọc dữ liệu từ các file trung gian
- Xử lý dữ liệu từ các file trung gian: Thực hiện Reduce
- Tập hợp kết quả output của reduce để cho ra kết quả cuối

Mô hình MapReduce sẽ là bộ khung, người lập trình sẽ cung cấp cho bộ khung đó những thứ sau:
- Một tập hợp các file input hoặc một file input
- Hàm MapFunc(key, value): hàm này xử lý một key và value tương ứng rồi cho xuất ra một tập hợp các cặp key, value trung gian
- Hàm ReduceFunc(key, value[]): hàm này xử lý các value của cùng một key trung gian để cho ra value cuối cùng của key đó.
- Một số nReduce là số task reduce mà người dùng muốn.
Sau đây là ví dụ cụ thể về thuật toán MapReduce được dùng trong bài toán word count cơ bản, là bài toán đếm tổng số lần xuất hiện của từng từ trong một tập hợp các file text.
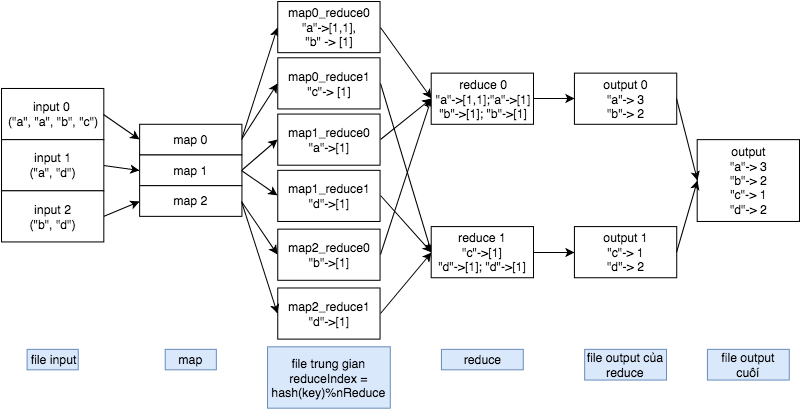
- Trong sơ đồ trên, ta giả dụ có 3 file input. Mỗi một map task xử lý một file input.
- Mỗi map task đọc một file. Giả sử, ta có nội dung các file như trên hình: file 1 có các từ “a”, “a”, “b”, “c”, tương tự với file 2 và file 3.
- Task map 1 đọc file 1, với mỗi một lần một từ xuất hiện, thêm giá trị 1 vào value của của từ đó. Như thế, map 1 sẽ có key “a” với value là [1,1], “b” có value [1], “c” có value là [1]. Tương tự như vậy với các task map còn lại.
- Sau đó, ta sắp xếp các key để sao cho mỗi key đều được xử lý bởi một task reduce duy nhất. Ở đây task reduce 0 xử lý key “a”, “b” còn task reduce 1 xử lý key “c”, “d”. Có một cách để cài đặt là: \(reduceIndex = hash(key) \% nReduce\)
- Mỗi task reduce xử lý nhiều key, với mỗi key thì task này dồn các value lại để ra 1 value duy nhất là số lần xuất hiện của của key đó.
- Bước cuối cùng là gộp tất cả các output ra thành một output cuối.
- Ta có thể thấy, có tổng cộng \(nMap * nReduce\) số file trung gian.
3. Làm quen với mã nguồn MapReduce
Mã nguồn của bài tập được lưu ở đây. Bạn cần có một git để clone về máy của mình, dùng lệnh sau:
git clone git://g.csail.mit.edu/6.824-golabs-2018 6.824
Phần mã nguồn này hỗ trợ chạy MapReduce theo hai cách, một là tuần tự, hai là phân tán.
- Cách thứ nhất, mô hình sẽ chạy các việc map và reduce lần lượt từng việc một. Ví dụ nếu có 3 task map và 2 task reduce, mô hình sẽ chạy task map1, map2, map3, rồi đến reduce1, reduce2, xong cái trước rồi mới đến cái sau.
- Cách thứ hai là chạy phân tán. Với cách này, mô hình này sẽ chạy các task map song song với nhau, mỗi task một thread. Khi tất cả các task map đã hoàn thành, nó sẽ bắt đầu chạy các task reduce, mỗi task một thread, song song với nhau. Khi tất cả các task reduce đã hoàn thành, nó sẽ gom output lại.
4. Map/Reduce input và output
Phần đầu tiên của bài tập chúng ta sẽ phải hoàn thiện mô hình MapReduce. Phần mô hình này còn thiếu hàm doMap() và hàm doReduce(). Để tránh hiểu nhầm, ở đây ta có doMap() và mapFunc(); cũng như doReduce() và reduceFunc().
- doMap() là hàm khung của mô hình để thực hiện một map task. Hàm này sẽ đọc input, gọi hàm mapFunc(), lấy output của hàm mapFunc(), sắp xếp/chia nhỏ ra để viết ra các file trung gian tương ứng.
- doReduce(), là hàm khung của mô hình để thực thi reduce task. Hàm này sẽ đọc input từ file trung gian, gọi reduceFunc() và lấy output của reduceFunc() viết ra các file output.
- mapFunc() và reduceFunc() là hàm thực thi job, do người dùng MapReduce cung cấp, tuỳ vào làm job gì mà viết hàm mapFunc() phù hợp.
Phần này sẽ trình bày sơ lược thuật toán của hai hàm doMap() và hàm doReduce() bằng pseudo-code.
doMap(inputFile, nReduce, mapIndex, mapFunc()):
content = read(inputFile)
mapFuncResult = mapFunc(inputFile, content) // return list, mỗi phần tử của list là một cặp KeyValue
for KeyValue in mapFuncResult:
reduceIndex = hash(KeyValue.Key) % nReduce
intermediate_file_name = "map" + mapIndex + "reduce" + reduceIndex // xây dựng tên file trung gian
write(intermediate_file_name, KeyValue)
doReduce(reduceIndex, nMap, reduceFunc()):
dict = {} // hash map key-> values
for mapIndex in (0, nMap):
// đọc input từ nMap file trung gian
intermediate_file_name = "map" + mapIndex + "reduce" + reduceIndex
content = read(intermedia_file_name)
for KeyValue in content:
dict[KeyValue].append(KeyValue.Value)
reduce_file_out = "reduce" + reduceIndex
for KeyValue.Key, values in dict:
reduceFuncResult = reduceFunc(KeyValue.Key, values) // return một value, là tổng hợp tất cả các value của một key
write(reduce_file_out, (Key reduceFuncResult))
Để kiểm tra xem mô hình có triển khai đúng không, chạy test và so sánh output với output sau:
$ env "GOPATH=$PWD/../../" go test -v -run Sequential
=== RUN TestSequentialSingle
master: Starting Map/Reduce task test
Merge: read mrtmp.test-res-0
master: Map/Reduce task completed
--- PASS: TestSequentialSingle (1.34s)
=== RUN TestSequentialMany
master: Starting Map/Reduce task test
Merge: read mrtmp.test-res-0
Merge: read mrtmp.test-res-1
Merge: read mrtmp.test-res-2
master: Map/Reduce task completed
--- PASS: TestSequentialMany (1.33s)
PASS
ok mapreduce 2.672s
5. Dùng MapReduce để viết bài toán word count - đếm từ
Bây giờ khi mô hình MapReduce đã hoàn tất, ta có thể viết các job để chạy trên MapReduce. Phần này sẽ trình bày bài toán đếm từ và thuật toán của hàm MapFunc() và hàm ReduceFunc(). Lưu ý là phần này sẽ làm MapReduce chạy Sequential - chạy tuần tự.
Bài toán này cho ta một tập hợp file input. Yêu cầu là ta phải đếm tổng số lần xuất hiện của từng từ một trong tất cả các file đó. Với mô hình MapReduce hoàn tất, mô hình sẽ làm cho ta tất cả mọi việc, bao gồm:
- Đọc input
- Gọi hàm MapFunc()
- Chia nhỏ output của MapFunc() ra các file trung gian
- Đọc input từ các file trung gian và phân phối cho hàm ReduceFunc()
- Gọi hàm ReduceFunc()
- Lấy output của hàm ReduceFunc() và dồn lại thành output cuối
Công việc của ta trong phần này là phải viết hàm MapFunc() và hàm ReduceFunc() để mô hình MapReduce có thể gọi. Hàm MapFunc() lấy input là một Key và một Value, trong đó Key ở đây là tên file input, Value là nội dung của file. Thực ra với cách triển khai mô hình MapReduce này, chúng ta không cần dùng đến Key mà chỉ quan tâm đến value, vì nội dung file đã được DoMap() đọc rồi. Ngoài ra, vì với mapFunc(), ta thêm 1 vào values với mỗi một lần key xuất hiện nên chỉ cần tính độ dài của values là biết key đó xuất hiện bao nhiêu lần. Sau đây là pseudo-code.
mapFunc(Key, Value):
output = [] // list với mỗi phần tử là một cặp KeyValue
words = split(Value) // chia nội dung file ra thành từng từ
for word in words:
KeyValue = (word, 1)
output.append(KeyValue)
return output
reduceFunc(Key, Value[]):
return len(Value[])
Với hai hàm mapFunc() và reduceFunc() hoàn tất, mô hình MapReduce này sẽ đọc được số lần xuất hiện của từng từ trong tất cả các file input. Để kiểm tra xem kết quả, ta chạy lệnh sau để thực hiện word count và xem kết quả. File output sẽ tên là mrtmp.wcseq
$ cd "$GOPATH/src/main"
$ time go run wc.go master sequential pg-*.txt
master: Starting Map/Reduce task wcseq
Merge: read mrtmp.wcseq-res-0
Merge: read mrtmp.wcseq-res-1
Merge: read mrtmp.wcseq-res-2
master: Map/Reduce task completed
2.59user 1.08system 0:02.81elapsed
$ sort -n -k2 mrtmp.wcseq | tail -10
that: 7871
it: 7987
in: 8415
was: 8578
a: 13382
of: 13536
I: 14296
to: 16079
and: 23612
the: 29748
6. Kết luận
Đây là một bài tập khá thú vị (và không hề dễ dàng) giúp chúng ta hiểu về mô hình MapReduce và cách triển khai MapReduce với ngôn ngữ Go. Bài tập đòi hỏi người làm phải tự đọc hiểu mã nguồn và tra cứu tài liệu để viết chương trình với Go, nếu bạn chưa dùng Go bao giờ.
Mô hình này còn có thể chia nhỏ việc và chạy việc song song, tận dụng CPU để giảm thời gian thực thi. Bạn đọc có thể xem chi tiết đề bài tập trong phần tham khảo.
7. Tham khảo
[1] “Lab 1: MapReduce” http://nil.csail.mit.edu/6.824/2018//labs/lab-1.html